Enlace del desarrollo alojado en GIT HUB
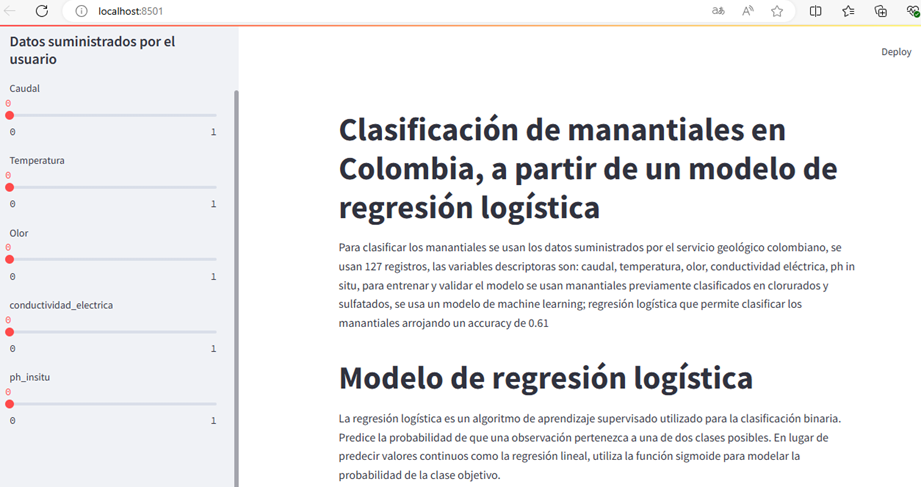
Para clasificar los manantiales se usan los datos suministrados por el servicio geológico colombiano, se usan 127 puntos, las variables descriptoras son: caudal, temperatura, olor, conductividad eléctrica, ph in situ, para entrenar y validar el modelo se usan manantiales previamente clasificados en clorurados y sulfatados, se usa un modelo de machine learning; regresión logística que permite clasificar los manantiales arrojando un accuracy de 0.61.
Modelo de regresión logística
La regresión logística es un algoritmo de aprendizaje supervisado utilizado para la clasificación binaria. Predice la probabilidad de que una observación pertenezca a una de dos clases posibles. En lugar de predecir valores continuos como la regresión lineal, utiliza la función sigmoide para modelar la probabilidad de la clase objetivo.
Desarrollo de la aplicación
Para desarrollar la aplicación, se usa el archivo “datos_manantiales.csv”,la cual contiene 5 variables a partir de los cuales se va a generar el modelo. Para el despliegue se usa la librería streamlit de Python que permite desarrollar aplicaciones web a partir de modelos de inteligencia artificial deforma ágil.
En el primer plano se observa la introducción y en la parte izquierda el menú desplegable.
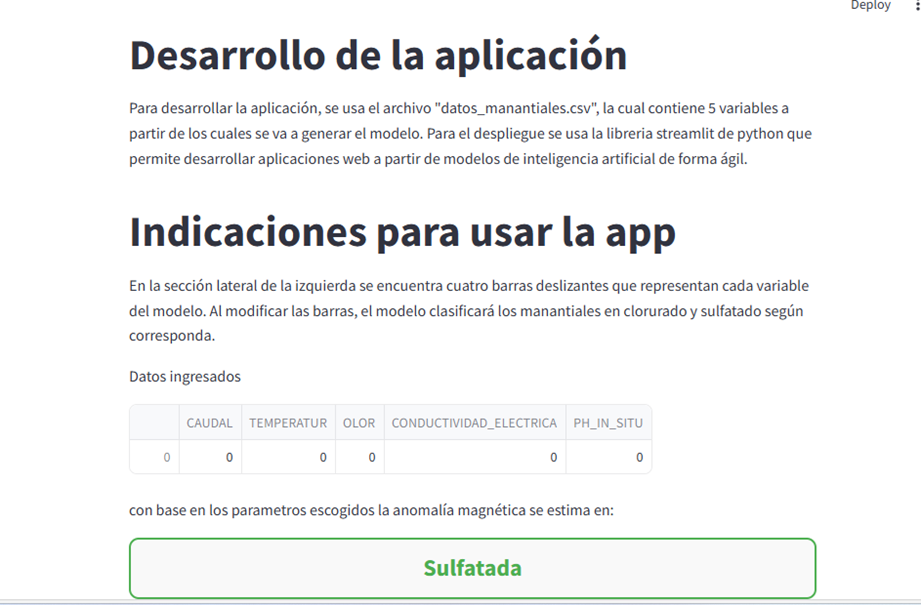
Indicaciones para usar la app
En la sección lateral de la izquierda se encuentra cuatro barras deslizantes que representan cada variable del modelo. Al modificar las barras, el modelo clasificará los manantiales en clorurado y sulfatado según corresponda. La variable olor tiene3 clasificaciones, siendo 0 no se percibe olor, 1 olor leve, y 2 hace referencia a olor fuerte.
Segundo plano: se observa el desarrollo de la aplicación, las indicaciones de uso y la clasificación de los manantiales.